This is the second metric, to quantify reputer stake’s being similar.
We take the reputer stakes as an input. For a metric I am using and improved version of the normalised entropy metric used for topics and validators. Since I am using entropy I am really working with stake fractions here. I assume the stakes follow a power law (using the same parameters as I did for topics).
Reminder of the PL parameters I used:
x_min = 1
log_xmax_xmin_range = np.arange(0.5, 3.5, 0.5)
alphas = [-1.01, -1.51, -2.01, -2.51, -3]
It is improved thanks to @Apollo11’s recommendation to scale the dynamic range: Reminder of the PL parameters I used:
x_min = 1
log_xmax_xmin_range = np.arange(0.5, 3.5, 0.5)
alphas = [-1.01, -1.51, -2.01, -2.51, -3]
It is improved thanks to dynamic range scaling via:

This was @Apollo11’s idea, thank you!!!
I am using C=100 for the simulations below. I am also testing two versions of entropy now:
Vanilla entropy:
def entropy(pmf):
return -np.sum(pmf * np.log(pmf))
The scaled entropy from the white paper:
def entropy_WP(pmf, beta):
N = len(pmf)
N_eff = 1/np.sum(pmf**2)
return -np.sum(pmf * np.log(pmf))*(N_eff/N)**beta
I used beta=0.25.
First vanilla entropy:
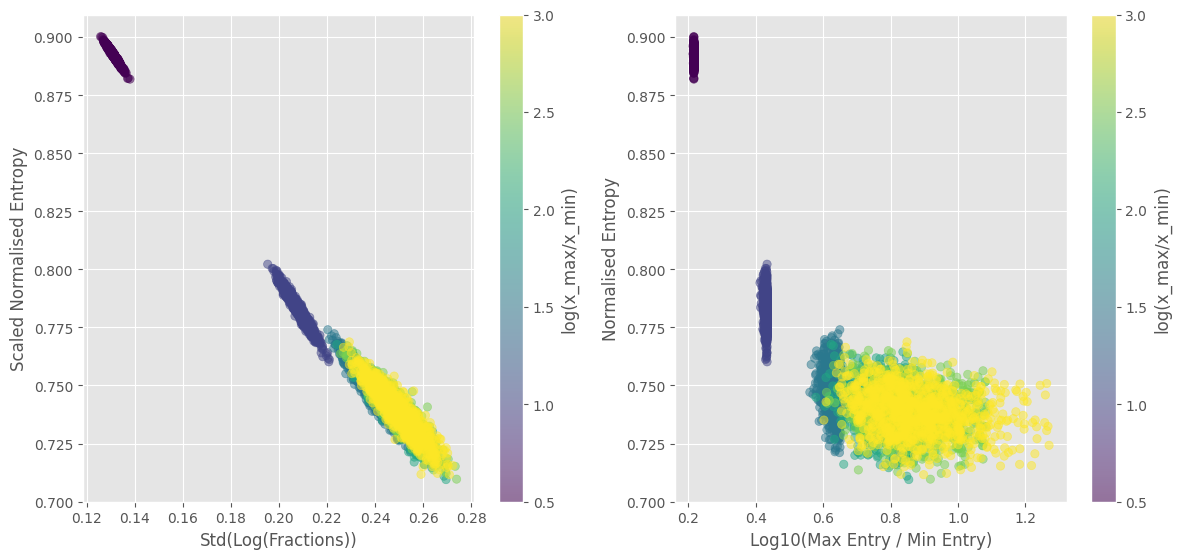
Here are the results for C=100, vanilla entropy, and 100 reputers:
Coloured by alpha:
Colorued by log(max/xmin):
Now results for C=100, vanilla entropy, and 2000 reputers:
Now results using entropy from the white paper:
C=100, white paper entropy, and 100 reputers:
C=100 seems to be much too large when using the white paper entropy, testing with C=10.
100 reputers:
2000 reputers:
I love how close to linear the left scatter plots are using the white paper entropy and C=10. I picked C arbitrarily based on observations. Not exactly sure how to pick the best C but I can experiment more. My concern with this metric is how the lower bound of the metric is around 0.4 for 2000 reputers, and 0.2 for 100 reputers. This does not occur using vanilla entropy and C=100. But this isn’t necessarily bad, a lower metric corresponds to less health, and 100 reputers is worse than 1000 reputers