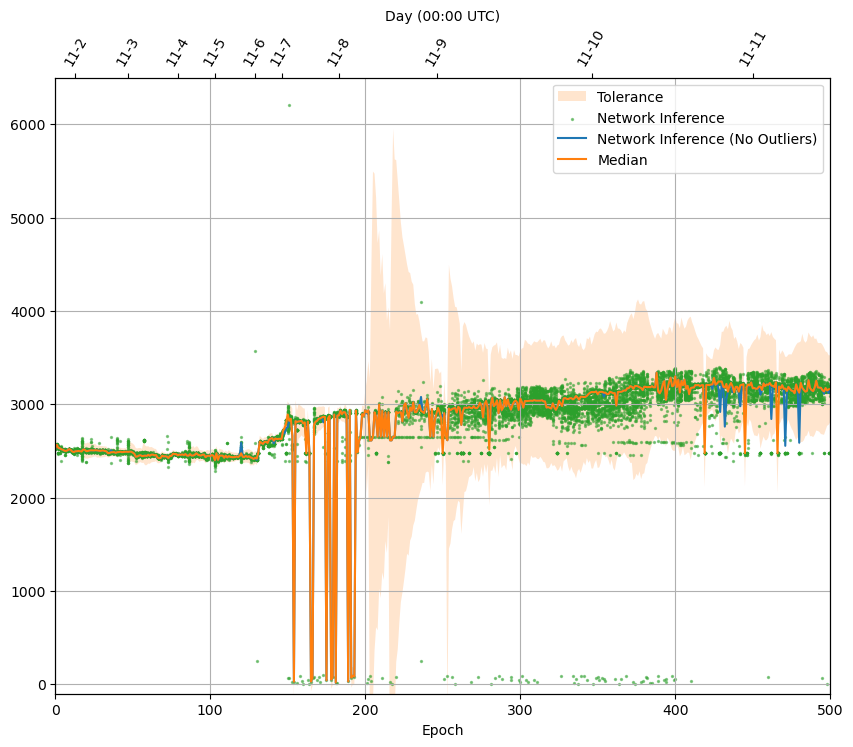
With this, here’s a description of the final method I recommend. I’ll first describe the “vanilla” smooth MAD method, as it makes it easier to understand the actual recommended method, which follows in point sections 2 & 3.
1. Detecting outliers (original smooth MAD method)
Short description: In every epoch, compute the median of the inferer predictions. Then subtract that from all predictions, take the absolute value of the results, and take the median of this list of values. That’s the median absolute deviation (MAD). Smooth the MAD using an EMA. Reject a prediction as an outlier if it differs from the median at least threshold times the smoothed MAD. I found threshold=11 to give good results in the simulator.
Now we describe this in more detail with pseudocode. The main ingredient is the median, which could e.g. be implement like this, for an array x:
def median(x):
x_sorted = sorted(x)
j = (len(x) - 1) // 2 # integer division (rounding down)
if len(x) % 2 == 1: # odd length
return x_sorted[j]
else: # even length
return 0.5 * x_sorted[j] + 0.5 * x_sorted[j+1]
Using this function, we can detect outliers with the following algorithm:
# the input is an array called `predictions`
# output is a boolean array `outlier` of the same length
threshold = 11.0
alpha = 0.2
mad_smooth = None # this has to be preserved across epochs
for each epoch: # it's not a big deal if we skip some epochs, just use the last value of mad_smooth available
median_prediction = median(predictions)
deviations = [abs(x - median_prediction) for x in predictions]
mad = median(deviations)
if mad_smooth is None:
mad_smooth = mad
else:
mad_smooth = alpha * mad + (1 - alpha) * mad_smooth
for i in range(len(predictions)):
if abs(predictions[i] - median_prediction) > threshold * mad_smooth:
outlier[i] = True # predictions[i] is an outlier!
else:
outlier[i] = False
2. Detecting outliers (“old and new” variation)
To mitigate problems with suddenly changing medians we can use this variation, which effectively does the outlier detection above with the previous epoch’s median in addition to the current one, and only declares an inference as an outlier if it one is by both measures.
It’s really just a few lines changed to the above, but we have to preserve an additional value last_median across epochs.
# the input is an array called `predictions`
# output is a boolean array `outlier` of the same length
threshold = 11.0
alpha = 0.2
mad_smooth = None # this has to be preserved across epochs
last_median = None # this also needs to be preserved
for each epoch: # it's not a big deal if we skip some epochs, just use the last value of mad_smooth and last_median available
median_prediction = median(predictions)
deviations = [abs(x - median_prediction) for x in predictions]
mad = median(deviations)
if mad_smooth is None:
mad_smooth = mad
else:
mad_smooth = alpha * mad + (1 - alpha) * mad_smooth
for i in range(len(predictions)):
if abs(predictions[i] - median_prediction) > threshold * mad_smooth and
(last_median is None or abs(predictions[i] - last_median) > threshold * mad_smooth):
outlier[i] = True # predictions[i] is an outlier!
else:
outlier[i] = False
last_median = median_prediction
3. Computing an outlier-resistant network inference using the outlier array (in both cases)
To get the outlier-resistant network inference we need to modify equations (3) and (9) from the whitepaper. In the whitepaper, they are
for computing the forecast-implied inferences and
for computing the combined network inference.
All we have to do is remove the outliers from each of the four sums, i.e.
Here OR stands for “outlier-resistant”. The second equation just looks more complicated because I chose to separate the sum into two sums, one over inferers (j) and one over forecasters (k).
In other words, we first need to compute outlier resistant versions for all the forecast-implied inferences (we don’t do outlier detection on forecasters themselves, but we need to modify the forecast-implied inferences to not include outlier inferers). Then we can use these to compute the outlier-resistant network inference.